이 가이드에서는 Data Flow architecture의 주요 개념을 설명합니다.
-
Data Flow의 서버 구성 요소
-
server components는 stream과 batch Job을 배포할 수 있는 application type 입니다.
-
배포된 application과 microservice architecture와 DLS을 사용하여 정의하는 방법
-
배포되는 platform
가이드의 다른 섹션에서는 아래의 내용을 설명합니다.
-
서버 구성 요소와 보안하는 방법과 서버 구성 요소와 상호 작용하는데 사용되는 도구(Tooling)
-
Streming data pipeline의 실시간 모니터링
-
Stream 과 Batch data pipeline 개발하는데 사용할 수 있는 Spring project
1. 서버 구성 요소 (Server Components)
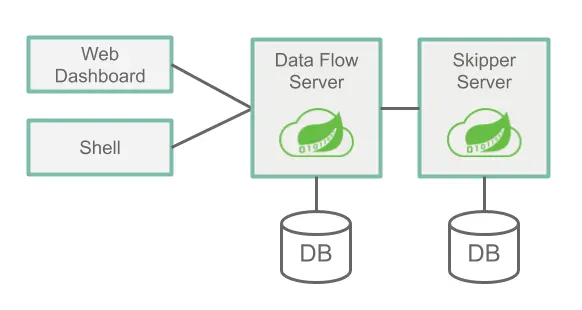
Data Flow는 2개의 main components를 가지고 있습니다.
-
Data Flow Server
-
Skipper Server
Data Flow에 접근하는 주요 진입점은 Data Flow Server의 RESTFul API 입니다.
web dashboard는 Data Flow Server에서 제공됩니다.
Data Flow Server와 Data Flow Shell application은 둘다 web API를 통해 통신합니다.
서버는 local machine, Cloud Foundry, Kubernetes와 같은 여러 플랫폼에서 실행할 수 있습니다.
각 서버는 관계형 데이터베이스에 상태를 저장합니다.
다음 이미지는 아키텍처의 high-level의 보기와 communication 경로를 보여줍니다.
Data Flow Server는 다음의 역할을 합니다.
-
DSL(Domain-Specific Language)에 기반하여 Stream과 Batch Job 정의 파싱
-
Stream, Task, Batch Job 정의를 검증하고 지속합니다.
-
jar, docker image와 같은 artifact를 DSL에 사용되는 이름에 등록
-
배치 작업을 하나 이상의 플랫폼에 배치
-
플랫폼에 작업 스케줄링 위임
-
자세한 작업 및 배치 작업 실행 기록을 쿼리
-
메시징 입력 및 출력을 ㅡ구성하고 배포 등록 정보 (예: 초기 인스턴스 수, 메모리 요구 사항 및 데이터 분할)를 전달하는 구성 등록 정보를 Streams에 추가
-
Skipper에 Stream 배포 위임
-
감사 작업 (예: Stream 만들기, 배포, 배포 취소 및 일괄 생성, 실행 삭제)
-
Stream, Batch Job DSL 탭 완성 기능 제공
Skipper Server는 다음의 역할을 합니다.
-
Stream을 하나이상의 플랫폼에 배포
-
blue/green 업데이트 전략에 기반한 상태 시스템을 사용하여 하나 이상의 플랫폼에서 Stream을 upgrade하고 rolling back
-
각 Stream의 manifest file(어떤 application이 배포되었는지에 대한 final description을 보여줌)의 히스토리 저장
1.1. Database
Data Flow Server와 Skipper Server는 RDBMS가 필요합니다.
기본 설정은 H2 내장 Database를 사용합니다.
외부 database를 사용하도록 서버를 구성할 수 있습니다.
지원되는 database는 H2, HSQLDB, MySQL, Oracle, PostgreSQL, DB2 및 SqlServer 입니다.
각 서버가 시작할 때 schema가 자동으로 생성됩니다.
1.2. Security
Data Flow와 SkipperServer는 OAuth 2.0 인증을 사용하여 관련 Rest endpoint를 보호합니다.
기본 인증을 사용하거나 OAuth2 access token을 사용하여 access 할 수 있습니다.
OAuth 공급자의 경우 포괄적인 LDAP 지원을 제공하는 CloudFoundry 사용자 계정 및 인증 (UAA) 서버를 사용하는 것이 좋습니다.
필요에 따라 보안 기능을 구성하는 방법에 대한 자세한 내용은 reference guide의 Security Section을 참조하세요.
| 기본 설정의 경우 Rest endpoint(adminitration, management, health)와 Dashboard UI는 인증된 access 가 필요하지 않습니다. |
2. Application Types
application은 두가지 형태가 있습니다.
-
Long-lived applications. 2가지 타입의 long-lived application이 있습니다.
-
단일 input 또는 output을 통해 무제한의 data가 소비되거나 생성되는 Message-driven application
-
다중 input, output을 가질 수 있는 Message-driven application. 또는 messaging middleware를 전혀 사용하지 않는 응용 프로그램
-
-
Short-lived applications은 유한한 data 집합을 처리한 다음 종료합니다. 두가지 변형이 있습니다.
-
code를 실행하고 Data Flow database에 실행 상태를 저장하는 형태. 선택적으로 Spring Cloud Task framework를 사용할 수 있고 java application일 필요는 없습니다. 그러나 응용 프로그램은 Data Flow의 database에 실행 상태를 저장해야 합니다.
-
batch processing에 수행을 기반하여 Spring Batch framework를 포함한 첫 번째의 확장
-
Spring Cloud Stream framework 및 Spring Cloud Task 또는 Spring Batch framework를 기반으로 하는 Short-lived application을 기반으로 Long-lived application을 작성하는 것이 일반적입니다.
Documentation에는 data pipeline을 개발할 때 이러한 framework를 사용하는 방법을 보여주는 guide가 많이 있습니다.
그러나 Spring을 사용하지 않는 long-lived, short-lived application을 작성할 수도 있습니다.
또한 다른 프로그래밍 언어로도 작성할 수도 있습니다.
runtime 에 따라 두가지 방법으로 application을 package 할 수 있습니다.
-
Maven repository, file location 또는 Http를 통해 액세스 할 수 있는 Spring Boot uber-jar
-
Docker registroy에서 호스팅되는 Docker image
2.1. Long-lived Applications
Long-lived Applications은 계속해서 실행되어야 합니다.
만약 application이 중지되면 platform이 다시 시작할 수 있어야 합니다.
Spring Cloud Stream framework는 공통 message system에 연결된 message-driven microservice application의 작성을 단순화하는 프로그래밍 모델을 제공합니다.
명확한 미들웨어에 불가지론적인 핵심 비즈니스 로직을 작성할 수 있습니다 (? You can write core business logic that is agnostic to the specific middleware.)
미들웨어는 application에 대한 Spring Cloud Stream Binder 라이브러리의 dependency를 추가하여 사용할 수 있습니다.
다음과 같은 messaging middleware 제품에 대한 binding library가 있습니다.
-
RabbitMQ
-
Kafka
-
Kafka Streams
-
Amazon Kinesis
-
Google Pub/Sub
-
Solace PubSub+
-
Azure Event Hubs
| Data Flow Server 는 long-lived application을 배포하기 위해 Skipper server에 위임합니다. |
2.1.1. Streams with Sources, Processors and Sinks
Spring Cloud Stream은 코드에서 message exchange pattern즉 application의 input과 output을 캡슐화하는 binding interface의 개념을 정의합니다.
Spring Cloud Stream은 다음과 같은 common message exchange 계약에 해당하는 몇가지 binding interface를 제공합니다.
-
Source : 대상에 message를 보내는 message producer
-
Sink : 대상에서 message를 읽는 message consumer
-
Processor : Source와 Sink의 조합. processor는 대상에서 message를 소비하고 다른 대상으로 보낼 message를 생성합니다.
Data Flow는 등록된 application의 type을 설명하기 위해 source, processor, sink를 사용하여 사용하여 등록합니다.
다음 예제는 http source(HTTP 요청을 수신 대기하고 HTTP payload 대상으로 보내는 application)와 log sink 를 등록하기 위한 shell 구문을 보여줍니다.
dataflow:>app register --name http --type source --uri maven://org.springframework.cloud.stream.app:http-source-rabbit:1.2.0.RELEASE
Successfully registered application 'source:http'
dataflow:>app register --name log --type sink --uri maven://org.springframework.cloud.stream.app:log-sink-rabbit:1.1.0.RELEASE
Successfully registered application 'sink:log'http와 log를 Data Flow에 등록하면 다음과 같이 pipes와 filters 구문을 사용한 Stream Pipeline DSL을 사용하여 stream 정의를 생성할 수 있습니다.
dataflow:>stream create --name httpStream --definition "http | log"http | log의 pipe 기호는 source의 output을 sink의 input으로 연결을 나타냅니다.
Data Flow는 stream을 배포할 때 적절한 properties를 설정하여 messaging middleware를 통해 source가 sink와 연결할 수 있게 합니다.
2.1.2. Streams with Multiple Inputs and Outputs
Sources, Sink 및 Processors는 모두 단일 output, 단일 input, 또는 둘다 있습니다.
이 것이 Data Flow가 output 대상을 input 대상과 짝을 이뤄 application property를 설정하게 합니다.
하지만 message processing application은 한개 이상의 input과 output 대상이 있을 수 있습니다.
Spring Cloud Stream은 custom binding interface를 정의할 수 있도록 지원합니다.
multiple input을 가진 application을 포함한 stream을 정의하려면 source, sink, processor 타입 대신 app 타입을 사용해야 합니다.
stream 정의는 single pipe 기호(|)를 대신 double pipe 기호(||)를 사용합니다. Stream Application DSL을 사용합니다.
||는 application 간 암묵적인 연결 없이 병렬을 의미한다고 생각하십시요.
다음 예제에서는 가상의 'orderStream’을 보여줍니다.
dataflow:>stream create --definition "orderGeneratorApp || baristarApp || hotDrinkDeliveryApp || coldDrinkDeliveryApp" -- name orderStream| 기호로 정의했을 때는 하나의 output은 항상 하나의 input과 쌍을 이루기 때문에Data Flow는 DSL을 사용하여 인접한 application과 통신하도록 stream에서 각 application을 설정할 수 있습니다.
|| 기호를 사용할 때는 여러 output 및 input 대상을 쌍으로 구성하는 configuration properties를 제공해야 합니다.
| Stream ApplicationDSL을 사용하고 messaging middleware를 사용하지 않는 application을 배포하여 single application으로 stream을 만들 수 있습니다. |
이 예제는 long-lived application 유형에 대한 일반적인 의미를 제공합니다.
추가적인 guide는 long-lived application을 개발, 테스트 및 등록하는 방법과 배포하는 방법에 대해 자세히 설명합니다
다음 주요 섹션에서는 배포된 stream의 runtime architecture에 대해 설명합니다.
2.2. Short-lived Applications
Short-lived application은 일정 기간 (수분에서 수시간) 실행된 다음 종료됩니다.
일정(예: 매주 평일 오후 6시에 실행)이나 이벤트(예: FTP 서버에 파일이 생성된 경우)에 따라 실행될 수 있습니다.
Spring cloud Task framework는 short-lived application의 life cycle event(예: 시작 시간, 종료 시간 및 종료 코드)를 기록하는 show-lived microservice을 개발할 수 있게 합니다.
task application은 application의 type을 설명하는 task라는 이름으로 Data Flow 에 등록됩니다.
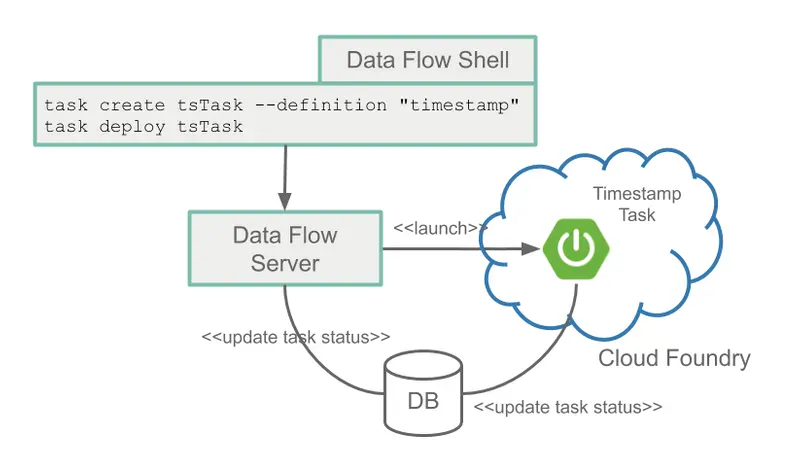
다음 예는 timestamp task(현재 시간을 출력하고 종료하는 application)를 등록하는 shell 구문입니다.
dataflow:>app register --name timestamp --type task --uri maven://org.springframework.cloud.task.app:timestamp-task:1.3.0.RELEASEtask 정의는 다음 예제와 같이 task의 이름을 참조하여 작성됩니다.
dataflow:>task create tsTask --definition "timestamp"Spring Batch framework는 아마 short-lived application을 작성하는 Spring 개발자들에게 떠오르는 것일 겁니다.
Spring Batch는 Spring Cloud Task보다 훨씬 풍부한 기능 set을 제공하며 대량의 데이터를 처리할 때 권장됩니다.
사용 사례는 많은 CSV 파일을 읽고 각 데이터 행을 변환하고 각 변환된 행을 database에 저장하하는 것입니다.
Spring Batch는 Spring Batch job의 실행에 대한 훨씬 더 풍부한 정보 set과 함께 자체 database schema를 제공합니다
Spring Cloud Task는 Spring Batch와 통합되어 Spring Cloud Task applicatino이 Spring Batch Job을 정의하면 Spring Cloud Task와 Spring Cloud Batch 실행 테이블 사이의 링크가 생성됩니다.
Spring Batch를 사용하는 task는 이전과 같은 방법으로 등록 및 생성됩니다.
| Spring Cloud Data Flow 서버는 작업을 platform으로 시작합니다. |
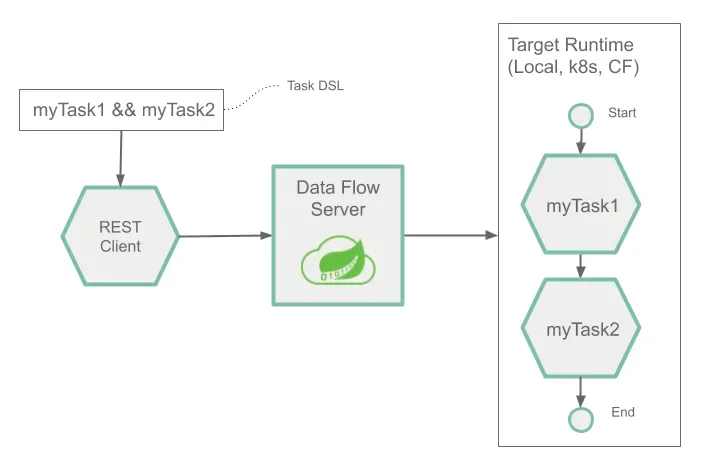
2.2.1. Composed Tasks
Spring Cloud Data Flow는 graph의 각 노드가 task application인 directed graph를 작성할 수 있게 합니다.
이것은 composed task에 대해 Composed Task Domain Specific Language 를 사용하여 수행됩니다.
Composed Task DSL에는 전체 흐름을 결정하는 여러 기호가 있습니다.
다음 예제에서는 이중 앰퍼센드 기호 (&&)를 조건부 실행에 사용하는 방법을 보여줍니다.
dataflow:>task create simpleComposedTask --definition "task1 && task2"DSL 표현식 (task1 && task2) 는 task1이 성공적으로 진행된 경우에만 task2가 실행된다는 것을 의미합니다.
task의 graph는 Composed Task Runner라는 task application을 통해 실행됩니다.
추가적인 guide는 short-lived application을 개발, 테스트 및 등록하는 방법과 배포하는 방법에 대해 자세히 설명합니다.
3. PreBuild Applications
개발을 시작하려면 많은 사전 구축된 application을 사용하여 일반적인 data source 및 sink와 통합할 수 있습니다.
예를 들어 cassandra data를 쓰는 cassandra sink와 groovy script를 사용하여 들어오는 data를 변환하는 processor를 사용할 수 있습니다
installation instruction은 이러한 applicatino을 Spring Cloud Data Flow에 등록하는 방법을 보여줍니다.
4. Microservice Architectural Style
Data Flow와 Skipper server는 각각 자신의 프로세스에서 실행되는 microservice application의 모음으로 플랫폼에 Stream 및 Composed Batch Job을 배포합니다.
각 microservice application은 다른 application과 독립적으로 scale up또는 scale down 할 수 있으며 각 application마다 고유한 versioning lifecycle이 있습니다.
Skipper는 런타임에 stream의 각 application을 개별적으로 업그레이드하거나 롤백할 수 있습니다.
Spring Cloud Stream과 Spring Cloud Task를 사용할 때 각 microservice application은 기본 라이브러리로서 Spring Boot를 기반으로 구축됩니다.
따라서 health check, security, configurable logging, monitoring 및 관리 기능 뿐만 아니라 executable jar packaging과 같은 모든 microservice application 기능이 제공됩니다.
이러한 microservice application은 java -jar 에 적절한 구성 속성을 사용하고 전달하여 스스로 실행할 수 있는 단순한 applicatinon임을 강조하는 것이 중요합니다.
데이터 처리를 위해 microservice application을 만드는 것은 다른 Spring Boot Applicatino을 만드는 것과 비슷합니다.
Spring Initializer 웹사이트를 사용하여 Stream 기반 또는 Task 기반 microservice의 기본 scaffolding을 만들 수 있습니다.
Data Flow 및 Skipper server는 각 applicatino에 적절한 application properties를 전달하는 것 외에도 대상 플랫폼의 infrastructure를 준비해야 합니다.
예를 들어 Cloud Foundry에서는 지정된 service를 applicatino에 binding합니다. Kubernetes의 경우 배포 및 service resource가 생성됩니다.
Data Flow Server는 대상 건타임에 여러 관련 application을 간단하게 배포하고 필요한 input, output 항목, 파티션 및 metric 기능을 설정하는데 유용합니다.
그러나 각 microservice application을 수동으로 배포하고 Data Flow나 Skipper를 사용하지 않을 수도 있습니다.
이 방법은 소규모 배포를 시작할 때 더 많은 application을 개발할 때 Data Flow의 편리성과 일관성을 점진적으로 채택하는 것이 더 적절할 수 있습니다.
Stream 및 Task 기반 microservice를 수동으로 배포하는 것도 Data Flow server가 제공하는 자동화된 application 설정과 플랫폼 대상 지정 단계를 더 잘 이해하는데 도움이 되는 유용한 교육 방법입니다.
stream 및 Batch 개발자 guide는 이 방법을 따릅니다.
4.1. Comparison to Other Architectures
Spring Cloud Data Flow의 architectural type은 다른 Stream 과 Batch processing platform과 다릅니다.
예를 들어 Apache Spark, Apache Flink 및 Google Cloud Dataflow 에서 application은 전용 comopute engine cluster에서 실행됩니다.
computing engine 특성 상 이러한 플랫폼은 Spring cloud Data Flow와 비교하여 복잡한 계산을 수행하기 위한 보다 풍부한 환경을 제공하지만 데이터 중심 application을 생성 할 때 종종 필요하지 않은 다른 실행 환경의 복잡성을 초래합니다.
그렇다고 Sprnig Cloud Data Flow를 사용할 때 실시간 데이터 계산을 할 수 없다는 것을 의미하지는 않습니다.
예를 들어 kafka Streams API를 사용하는 application을 개발하면 time-sliding-window와 moving-average 기능 뿐만 아니라 들어오는 메시지와 참조 데이터 집합의 조인이 가능합니다.
이 접근 방식의 이점은 인기있는 플랫폼을 실행 런타임으로 위임할 수 있다는 것입니다.
Data Flow는 해당 기능 집합 (resilience, scalability)뿐만 아니라 이미 다른 플랫폼에서 사용하고 있는 지식을 활용할 수 있습니다.
따라서 다른 end-user / web application을 배포하는데 사용되는 것과 동일한 기술을 적용할 수 있으므로 데이터 중심 application을 만들고 관리할 때 인식 격차가 줄어듭니다.
4.2. Streams
다음 이미지는 간단한 Stream의 runtime architecture를 보여줍니다.
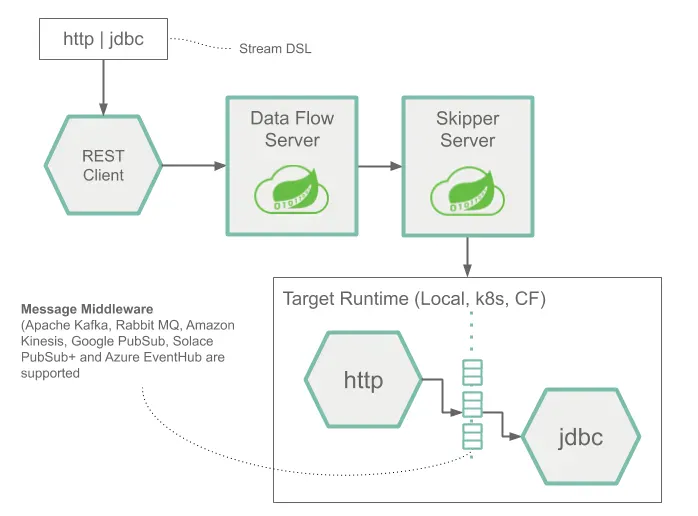
Stream DSL은 POST로 Data Flow Server에 보내집니다.
Maven 및 Docker atifact에 대한 DSL application 이름 매핑을 기반으로 http source와 jdbc sink application이 Skipper에 의해 대상 플랫폼에 배포됩니다.
HTTP application에 post된 데이터는 database에 저장됩니다.
| http source 및 jdbc sink application은 지정된 플랫폼에서 실행되며 Data Flow나 Skipper server에 어떤 연관도 없습니다. |
다중 input 과 output을 가질 수 있는 application으로 구성된 stream의 runtime architecture는 아래와 같습니다.
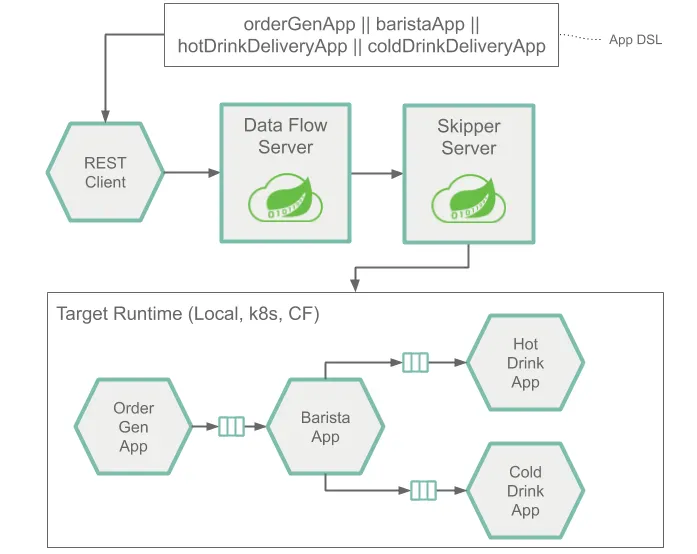
source, sink 또는 processor application을 사용할 때와 동일한 구조입니다.
이 architecture를 정의하기 위한 Stream application DSL은 단일 파이프 기호(|) 대신 이중 파이프 기호(||)를 사용합니다.
또한 이 Stream을 배포할 때 messaging system을 사용하여 각 application을 다른 application에 연결하는 방법을 설명하는 더 많은 정보를 제공해야 합니다.
5. Platforms
Spring Foundry, Kubernetes 및 local Machine에 Spring Cloud Data Flow server와 Skipper server를 배포할 수 있습니다.
또한 이러한 서버에 의해 배포된 application을 여러 플랫폼에 배포할 수도 있습니다.
-
Local: local machine, Cloud Foundry 또는 Kubernetes에 배포할 수 있습니다.
-
Cloud Foundry: Cloud Foundry 또는 Kubernetes에 배포할 수 있습니다.
-
Kubernetes: Kubernetes 또는 Cloud Foundry에 또는 배포할 수 있습니다.
가장 일반적인 architecture는 application을 배포하는 동안 여러 Cloud Foundry 조직, 공간 및 기판과 여러 Kubernetes cluster에 배포할 수 있습니다.
HashiCorp, Nomad, Red Hat OpenShift 및 Apache Mesos와 같은 다른 플랫폼에 배포할 수 있는 커뮤니티 구현이 있습니다.
|
로컬 서버는 Spring Batch admin project를 대신하여 Task 배포를 위해 production 환경에서 지원됩니다. Strem 배포를 위해 production에서 로컬 서버가 지원되지 않습니다. |